In this post I’ll explain something folkloric: that you can pretend that the continuation monad is a probability monad, and do probabilistic programming in it. Unlike more obvious representations of probability like the one in Numeric.Probability.Distribution via lists, this way works equally well for continuous as for discrete distributions (as long as you don’t mind numerical integration). The post is a literate Haskell program, which is an expanded version of this repository. It’s a sort of sequel to my very first blog post, Abusing the continuation monad.
I mentally call this idea “synthetic measure theory” or sometimes “synthetic probability”, although as far as I know it is not related to various Google hits for those terms such as this, or this. (But one of the hits is this paper, which is probably related.)
Since this post is literate Haskell, we’d better get some imports out of the way. Obviously,
import Control.Monad.Cont
Later, to avoid the headache of hacking up a bad trapezium method by hand, we’ll also need
import Numeric.Tools.Integration
The mathematical fact behind “synthetic measure theory” is called the Riesz representation theorem, which says roughly that measures are equivalent to linear functionals. Every measure 

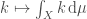

This probably sounds as clear as mud, because measure theory is very esoteric, but I’ll illustrate it by example through the rest of this post.
In Haskell, the type of the integration operator is (X -> Double) -> Double, also known as Cont Double X. For the Riesz theorem to work it is crucial that the second -> refers only to functions that are linear (in the sense of linear algebra). We can’t do that in Haskell (or at least if we can then I don’t know how to do it), so we have a lossy representation and must rely on the user not to write anything that isn’t linear.
So let’s define a probability monad like this:
type Prob = Cont Double
The general idea, with the scary words removed, is that we represent a probability distribution using the operator that does integration weighted by that probability distribution. Here, for example, is the operator that represents an unbiased coin flip:
data Coin = Heads | Tails deriving (Eq, Show)
flip :: Prob Coin
flip = cont $ \k -> (k Heads + k Tails) / 2
More generally, we can represent the discrete uniform distribution on any finite set of points:
uniformDiscrete :: [a] -> Prob a
uniformDiscrete xs = cont $ \k -> sum (map k xs) / fromIntegral (length xs)
(where fromIntegral doesn’t actually do anything, just wrangling different number types). We could if we wanted also abuse uniformDiscrete to represent non-uniform distributions by giving it a list with repeated elements.
An event is a predicate, i.e. a function into booleans. In order to get the probability of an event, we integrate its “indicator function”, i.e. the equivalent function into 1 and 0:
probability :: Prob a -> (a -> Bool) -> Double
probability integrate p = runCont integrate $ \x -> if p x then 1 else 0
With this, we can run probability coin (== Heads) and get the answer 0.5. For dice rather than coins we can run probability (uniformDiscrete [1..6]) even, and also get the answer 0.5.
If we have a distribution on Doubles we can also easily get its expectation, by integrating the identity function:
expectation :: Prob Double -> Double
expectation integrate = runCont integrate id
For example, to get the expected value of a dice roll we can run expectation (uniformDiscrete [1.0 .. 6.0]) and be correctly told 3.5. (It’s best not to think too hard about how the Haskell Prelude installs instance Enum Double by default.)
The other mathematical fact behind the whole thing is that integration defines a monad morphism from the probability monad (any of them, including the ones that can’t be expressed in Haskell) to the continuation monad. This fact packages up a whole lot of information saying that the monad structure of the continuation monad does the right thing on (things that represent) probability distributions. What that means in practice is that do-notation in the continuation monad can be used as a probabilistic programming language:
twoDice :: Prob Int
twoDice = do roll1 <- uniformDiscrete [1..6]
roll2 <- uniformDiscrete [1..6]
return (roll1 + roll2)
Then we can ask probability twoDice (== 6) and be told 0.13888888888888887, also known as 5/36. We can also run expectation (fmap fromIntegral twoDice) and be told 7.0.
Where this method really comes into its own is for representing continuous probability distributions. Here is the uniform distribution on the unit interval:
uniformUnitInterval :: Prob Double
uniformUnitInterval = cont $ \k -> quadBestEst (quadTrapezoid params (0, 1) k)
where params = QuadParam {quadPrecision = 0.00001, quadMaxIter = 30}
Although under the hood this now uses numerical integration, from the outside we can interact with it in exactly the same way as for discrete distributions. For example we can run probability uniformUnitInterval (<= 0.5) and get back 0.5000038146972656, which is close enough to a half for government work. Also expectation uniformUnitInterval gives 0.5 on the nose.
For a slightly less trivial example, I ran probability (do {x <- uniformUnitInterval; y <- uniformUnitInterval; return (x*y)}) (<= 0.5) for the product of two independent uniformly distribution random variables. For me this took several seconds before getting the answer 0.8465757742524147.
I wanted to demo a normal distribution for the grand finale, but I couldn’t find an existing density function for normal distributions written in Haskell, so I decided it would be too much effort.
Doing probability this way opens the Pandora’s box of numerical integration, of course. It occurs to me that if we used Monte Carlo integration rather than trapezium, this would start to blur the boundary between probabilistic programming and merely programming with a random number generator.
One last thing. Doing probabilistic programming in the continuation monad invites the question, what does call/cc do in probability?!? Unfortunately, after running an example I found that call/cc does not preserve linearity, so it is not a well-defined operation in probability. I’ll give the full demonstration, partly just as one more example of doing probability theory in this style.
The relevant type of call/cc here is ((a -> Prob b) -> Prob a) -> Prob a. A nontrivial example of something with the input type is Bayesian updating for arbitrary conditional distributions, given a fixed prior and observation. Fix
data X = X1 | X2 deriving (Eq, Show)
data Y = Y1 | Y2 deriving (Eq, Show)
prior = uniformDiscrete [X1, X2]
Supposing we observe the output Y1, for an arbitrary conditional distribution f :: X1 -> Prob X2 the posterior probabilities of X1 and X2 are respectively given by Bayes’ law:
px1 f = probability (f X1) (== Y1) * probability prior (== X1) / probability (prior >>= f) (== Y1)
px2 f = probability (f X2) (== Y1) * probability prior (== X2) / probability (prior >>= f) (== Y1)
For example, suppose we define the conditional distribution
f :: X -> Prob X2
f X1 = cont $ \k -> (2 * k Y1 + k Y2) / 3
f X2 = cont $ \k -> (k Y1 + 2 * k Y2) / 3
which represents the stochastic channel with scattering matrix 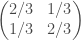
px1 f is 2/3 and px2 f is 1/3. (There might be a neater way to do Bayesian inversion in terms of integration operators, but I can’t think of it right now.)
The function bayes has type (X1 -> Prob X2) -> Prob X1, so callCC bayes has type Prob X1. Unfortunately it isn’t linear: the “total probability” probability (callCC bayes) (const True) is 1, but also probability (callCC bayes) (== X1) and probability (callCC bayes) (== X2) are both 1. So disappointingly, there’s no call/cc in probability.

https://hackage.haskell.org/package/monad-bayes-1.1.0/docs/Control-Monad-Bayes-Integrator.html now implements basically what you describe above, and let’s you work with the normal distribution (and most others). Some examples here: https://monad-bayes-site.netlify.app/introduction
LikeLike
Very cool, thanks!
LikeLike